3. 개념 잡기
3.1 Document 기반의 Key-Value 스토어
- 하나의 유니크한 키에 값을 저장
- 저장되는 값은 JSON 도큐먼트가 저장
- 키는 최대 250 바이트, 값의 경우에는 버킷의 경우 20MB, Memcached 방식의 버킷의 경우 1MB까지 저장 가능
- 저장할 때 키와 값뿐만 아니라 메타 데이터가 같이 저장되는데, 메타 데이터에는 CAS, TTL, Flag 3가지 값이 저장
- CAS는 데이터에 대한 일종의 타임 스탬프와 같은 개념으로 여러 클라이언트가 같이 데이터를 ACCESS 했을 때 일광성 문제가 생기는 것을 해결
- TTL은 데이터의 유효 시간을 정의. TTL 시간이 지나면 자동으로 삭제
- FLAG는 카우치베이스 클라이언트에서 사용하는 메타 데이터
- 이러한 메타 데이터(CAS, TTL, FLAG)는 60바이트의 메모리를 차지
- 모든 키와 메타 데이터를 메모리에 유지하기 때문에 데이터 모델링 또는 용량을 설계할 때 이 부분을 고려해서 RAM의 사이즈를 결정해야 함
3.2 버킷(Bucket)
- 일종의 RDBMS의 데이터베이스 같은 공간
- JSON 도큐먼트들은 이 버킷에 저장
- 각각의 버킷은 고유의 속성 값을 가지고 있음
- 하나의 클러스터에서 버킷은 최대 128개까지 생성할 수 있으나, 보통 성능상 10개를 권장
3.3 뷰(View)
- 뷰를 이용해서 RDBMS에서 제공되는 Indexing, Grouping, Sorting 등 가능
- RDBMS 뷰와 유사한 개념을 가짐
3.3.1 View basics

3.3.2 Development/Production Views
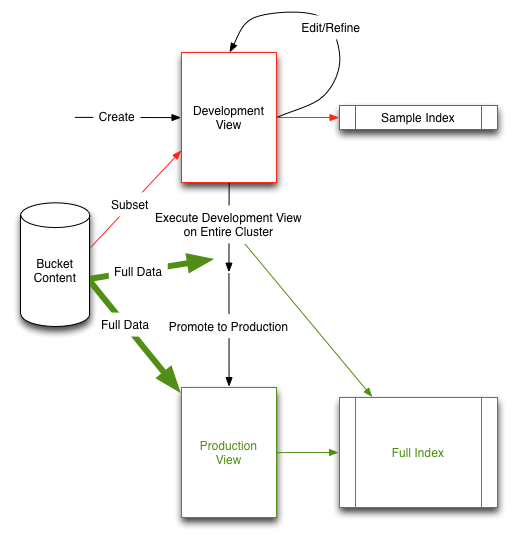
3.3.3 Writing views

3.3.3.1 Views operations
stale=ok

stale=false

stale=update_after

3.3.3.2 Views and stored data

3.3.4 Map functions
function(doc, meta)
{
emit(doc.name, [doc.city, doc.salary]);
}

3.3.5 Querying views
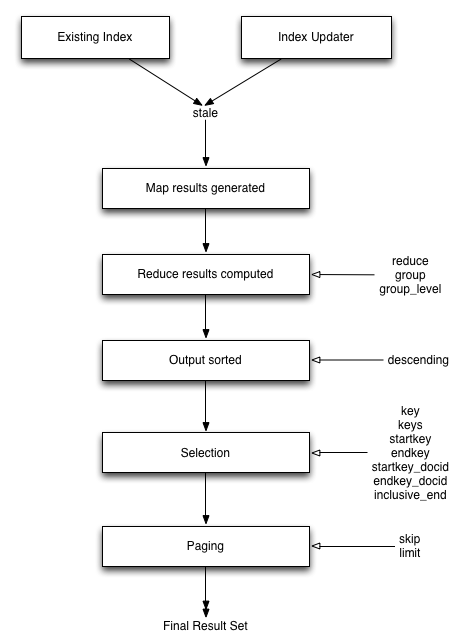
3.3.6 Reduce functions
- Built-in reduce functsions : _count, _sum, _stats
3.3.6.1 Built-in _count
using the input :
{ "rows" : [ {"value" : 13000, "id" : "James", "key" : ["James", "Paris"] }, {"value" : 20000, "id" : "James", "key" : ["James", "Tokyo"] }, {"value" : 5000, "id" : "James", "key" : ["James", "Paris"] }, {"value" : 7000, "id" : "Adam", "key" : ["Adam", "London"] }, {"value" : 19000, "id" : "Adam", "key" : ["Adam", "Paris"] }, {"value" : 17000, "id" : "Adam", "key" : ["Adam", "Tokyo"] }, {"value" : 22000, "id" : "John", "key" : ["John", "Paris"] }, {"value" : 3000, "id" : "John", "key" : ["John", "London"] }, {"value" : 7000, "id" : "John", "key" : ["John", "London"] }, ] }Enabling the reduce() function and using a group level of 1 would produce:
{ "rows" : [ {"value" : 3, "key" : ["Adam" ] }, {"value" : 3, "key" : ["James"] }, {"value" : 3, "key" : ["John" ] } ] }Using a group level of 2 would generate the following:
{ "rows" : [ {"value" : 1, "key" : ["Adam", "London"] }, {"value" : 1, "key" : ["Adam", "Paris" ] }, {"value" : 1, "key" : ["Adam", "Tokyo" ] }, {"value" : 2, "key" : ["James","Paris" ] }, {"value" : 1, "key" : ["James","Tokyo" ] }, {"value" : 2, "key" : ["John", "London"] }, {"value" : 1, "key" : ["John", "Paris" ] } ] }3.3.6.2 Built-in _sum
using the same sales source data, accessing the group level 1 view would produce the total sales for each salesman:
{ "rows" : [ {"value" : 43000, "key" : [ "Adam" ] }, {"value" : 38000, "key" : [ "James" ] }, {"value" : 32000, "key" : [ "John" ] } ] }Using a group level of 2 you get the information summarized by salesman and city:
{ "rows" : [ {"value" : 7000, "key" : [ "Adam", "London" ] }, {"value" : 19000, "key" : [ "Adam", "Paris" ] }, {"value" : 17000, "key" : [ "Adam", "Tokyo" ] }, {"value" : 18000, "key" : [ "James", "Paris" ] }, {"value" : 20000, "key" : [ "James", "Tokyo" ] }, {"value" : 10000, "key" : [ "John", "London" ] }, {"value" : 22000, "key" : [ "John", "Paris" ] } ] }
3.3.6.3 Built-in _stats
- Using the sales data, a slightly truncated output at group level one would be:
{ "rows" : [ { "value" : { "count" : 3, "min" : 7000, "sumsqr" : 699000000, "max" : 19000, "sum" : 43000 }, "key" : [ "Adam" ] }, { "value" : { "count" : 3, "min" : 5000, "sumsqr" : 594000000, "max" : 20000, "sum" : 38000 }, "key" : [ "James" ] }, { "value" : { "count" : 3, "min" : 3000, "sumsqr" : 542000000, "max" : 22000, "sum" : 32000 }, "key" : [ "John" ] } ] }
3.3.6.4 Handling re-reduce

3.3.7 Views in a schema-less database
For example, you could start storing name information using the following JSON structure:
{ "email" : "[email protected]", "name" : "Martin Brown" }A view can be defined that outputs the email and name:
function(doc, meta) { emit([doc.name, doc.email], null); }This generates an index containing the name and email information. Over time, the application is adjusted to store the first and last names separately:
{ "email" : "[email protected]", "firstname" : "Martin", "lastname" : "Brown" }The view can be modified to cope with both the older and newer document types, while still emitting a consistent view:
function(doc, meta) { if (doc.name && (doc.name != null)) { emit([doc.name, doc.email], null); } else { emit([doc.firstname + " " + doc.lastname, doc.email], null); } }